Message Queues and Asynchronous Processing
Low Altitude Flight Over the Messaging Queue Landscape
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Introduction
In a client-server architecture, the client can request a job to be done from the server by sending messages to the server.
Handling this communication can increase in complexity when you begin to manage the rate at which messages are sent, the number of requests a server can handle, or the response time that the client demands.
In this blog, we'll see one way to handle this intricacy.
What is Synchronous Processing?
In synchronous processing, a client sends a request to the server and waits for the server to complete its job and send back the response before the client can resume doing any other work.
This process is often referred to as a blocking request, as the client gets blocked from doing any other work until a response is received.

What is Asynchronous Processing?
Asynchronous processing is the exact opposite of synchronous processing. Here, the client doesn't wait for a response after sending a request to the server and continues doing any other work.
This process is referred to as a non-blocking request, as the execution thread of the client is not blocked. This allows systems to scale as more work can be done in a given amount of time.
Synchronous vs Asynchronous Processing
Synchronous requests block the execution thread of the client, forcing them to wait for the response to come before they can perform another action. On the other hand, asynchronous requests do not block and allow for more work to be done in a given time.
Since we do not know how much time the request will take, it is difficult to build responsive applications with synchronous processing. The more blocking operations, the slower the system becomes. With asynchronous processing, response time is quicker as the client does not have to wait for the request.
Fault tolerance of asynchronous processing is higher than that of synchronous processing, as it is easy to build a retry mechanism when a request fails.

What are Message Queues?
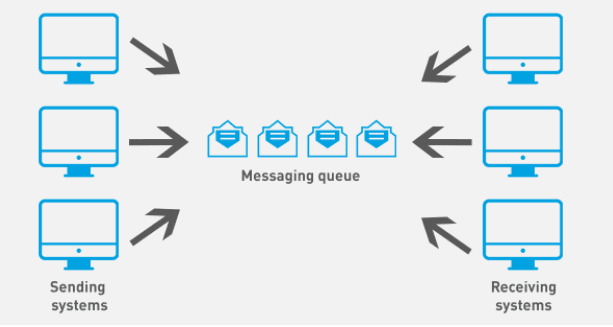
A message queue is a component that buffers requests from one service and broadcasts them asynchronously to another service.
Here, clients are the message producers, who send request messages to the queue instead of any server. They get an acknowledgment when the message is added to the queue, which enables them to continue with their other jobs without having to wait for the server.
Servers are known as message consumers and are served these messages from the queue based on the number of requests they can serve at any given time. This continues until all the messages in the queue have been served.
The two most common messaging queues are — RabbitMQ and Kafka.
Structure of Message Queues
A message queue is primarily a broker of messages between message producers and message consumers.
Each distinct entity in the messaging queue setup (producers, consumers, and queue) has a responsibility and they're decoupled from each other as much as possible.
The only contract between all entities is the messages for which the message queue facilitates the movement from producers to consumers.
In the following sections, we will discuss the responsibilities of each component and look at the various modes with which the message queue delivers a message to consumers.
Message Producers
Message producers initiate the asynchronous processing request. Producers have a responsibility to generate a valid message and publish it to the message queue. Messages submitted to the queue are then queued up and delivered to consumers to be processed asynchronously.
Producers communicate with message queues using the Advanced Message Queuing Protocol (AMQP).
Message Brokers
A message broker is simply just a queue. You can even implement a simple broker programmatically that buffers messages and sends them to consumers as and when needed.
Message brokers are the actual decoupling elements in the setup, sitting between and managing the process of communication between producers and consumers.
Because of their simplicity, brokers are optimized for high concurrency and throughput.
It is important to note that adding message brokers introduces an extra layer of complexity into your infrastructure and requires you to scale them as well. Brokers also have specific requirements and limitations when it comes to scalability.
Message Consumers
The main responsibility of consumers is to receive and process messages from the queue.
Most consumers are API services that perform that actual asynchronous processing.
Consumers can be implemented in different application languages or technologies and maintained independently from other components.
To achieve decoupling, consumers should know nothing about the producers. The only contract that should exist between the two is valid messages from the queue.
When properly decoupled, consumers can serve as independent service layers that can be used by both the message queue setup and other components in your infrastructure.
Consumer Communication Strategies
Message queues need to transmit messages down to consumers, depending on how application developers implement consumers, message queues have three distinct ways of delivering messages to the consumers:
- Pull Model
In this model, the consumer periodically checks the status of the queue. This is done at a scheduled interval programmed on the side of the consumer.
If there are messages found in the queue, the consumer picks them up until there are no more messages left to process, or when the 'N' number of messages has been consumed. This 'N' can be configured on the message broker.
- Push Model
Once a message is added, the consumer is notified and the message is then pushed down to it. Messages are pushed down to consumers at a rate at which the consumer can easily regulate.
- Subscription Model
In this model, consumers can subscribe to a topic. This publisher publishes a message to a topic rather than a queue. Each consumer connected to the broker maintains its private queue to receive messages from topics.
After the consumers subscribe to the topics and when a message is published to that topic, the message is cloned for each subscriber and added to the consumer’s private queue.
Comparing Different Message Brokers
As we have seen above, for asynchronous communication we usually need a message broker.
Below are the few considerations you have to look at when choosing a broker for managing your asynchronous operations:
Scale: The number of messages sent per second in the system
Data Persistency: The capability to recover messages
Consumer Capability: The capability to manage one-to-one / one-to-many consumers
RabbitMQ
Scale: Based on configuration and resources.
Persistency: Both persistent and transient messages are supported.
One-to-one vs One-to-many consumers: Both.
RabbitMQ supports all major languages, including Python, Java, .NET, PHP, Ruby, JavaScript, Go, Swift, and more.
Kafka
Scale: Can send up to a million messages per second.
Persistency: Yes.
One-to-one vs One-to-many consumers: Only one-to-many
Kafka has managed SaaS on both Azure and AWS. Kafka also supports all major languages, including Python, Java, C/C++, Clojure, .NET, PHP, Ruby, JavaScript, Go, Swift, and more.
Redis
Scale: Can send up to a million messages per second.
Persistency: Not supported (it’s an in-memory database).
One-to-one vs One-to-many consumers: Both.
Redis is a bit different from the other message brokers. Redis is an in-memory data store. Originally, Redis only supported one-to-one communication with consumers. However, since Redis 5.0 introduced the pub-sub, you can have one-to-many as another option.
Conclusion
In this blog, we covered how asynchronous processing is advantageous over its counterparts and how a message queue helps us achieve asynchronous processing along with keeping the different entities in its setup decoupled from each other.
We also covered some basic characteristics of the most commonly used message brokers: Redis, Kafka, and RabbitMQ.
Here's a bit more instruction for selecting the right message broker to use according to different use cases:
Short-lived Messages: Redis
- Redis is good for short-lived messages where persistence isn’t required.
Large Amounts of Data: Kafka
- Kafka is good for storing a large amount of data for long periods. Kafka is also ideal for one-to-many use cases where persistency is required.
Complex Routing: RabbitMQ
- RabbitMQ is good for complex routing communication.
Happy coding! 💻
(If you find any doubts, updates, or corrections to improve this article, Feel free to share them in the comments) 😊
Other Articles You Might Like
Generating unique IDs in a Large scale Distributed environment - A decent way to generate unique IDs across a distributed system that could also be used as the primary keys in the MySQL tables.
Javascript Clean Code Tips & Good Practices -15 tips I follow for writing better Javascript code.
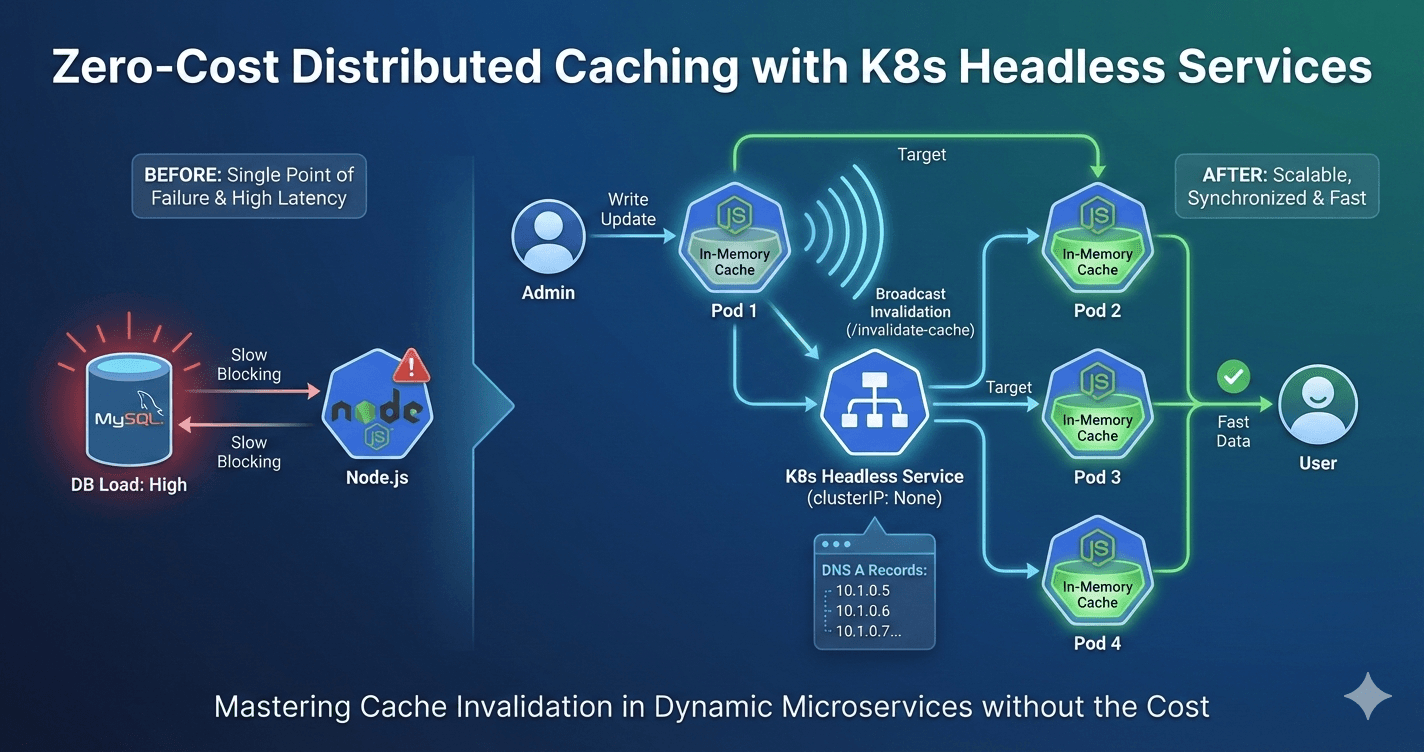
How we solved cache invalidation in Kubernetes with a headless service - A clever way we engineered to solve one of the finest computer science problems.
Welcome to the world of "NFTs" - Learn about what are NFTs and Why are they suddenly becoming the next big thing.
What is Blockchain Technology? Learn by creating one - Want to know how blockchain works?