

NanoID - A URL Friendly Unique Identifier
What is Nano Id and how is it different from UUID?

A
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Search for a command to run...
What is Nano Id and how is it different from UUID?
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Nano Ids are great indeed. I've started using them in some of my projects as well!
Bits and Pieces I learned on how to build and scale a distributed system. All the posts in the series belong to the real problems I faced during my 9-5 and the solutions we went through with.
Learn how to create unique IDs for a distributed system at a large scale using the Twitter snowflake
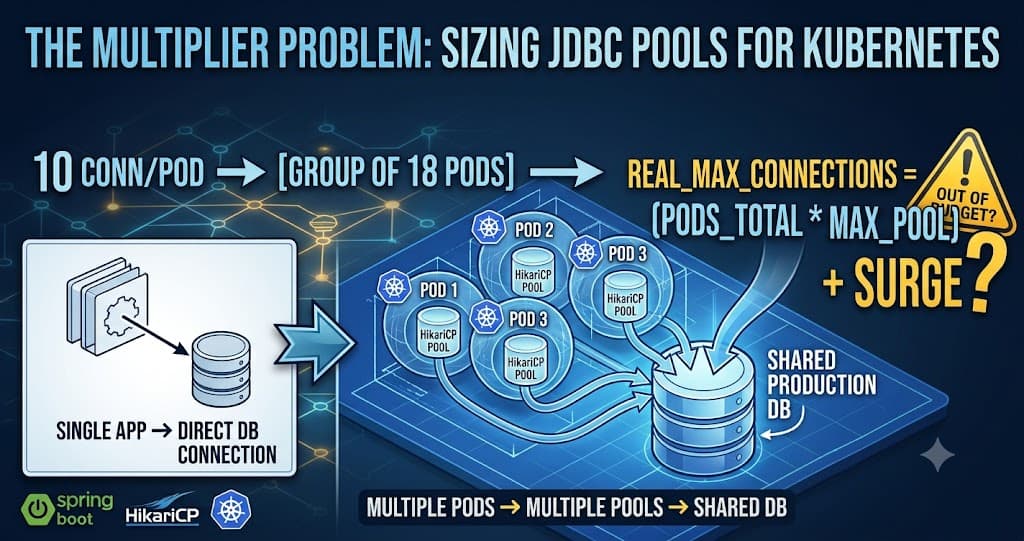
Stop guessing your maximum-pool-size. Learn how to calculate limits backwards from your database
Learn what Jib is, how it works, and when to use Jib vs Dockerfile. A guide with real-world scenarios

A prod debugging story you’ll probably relate to

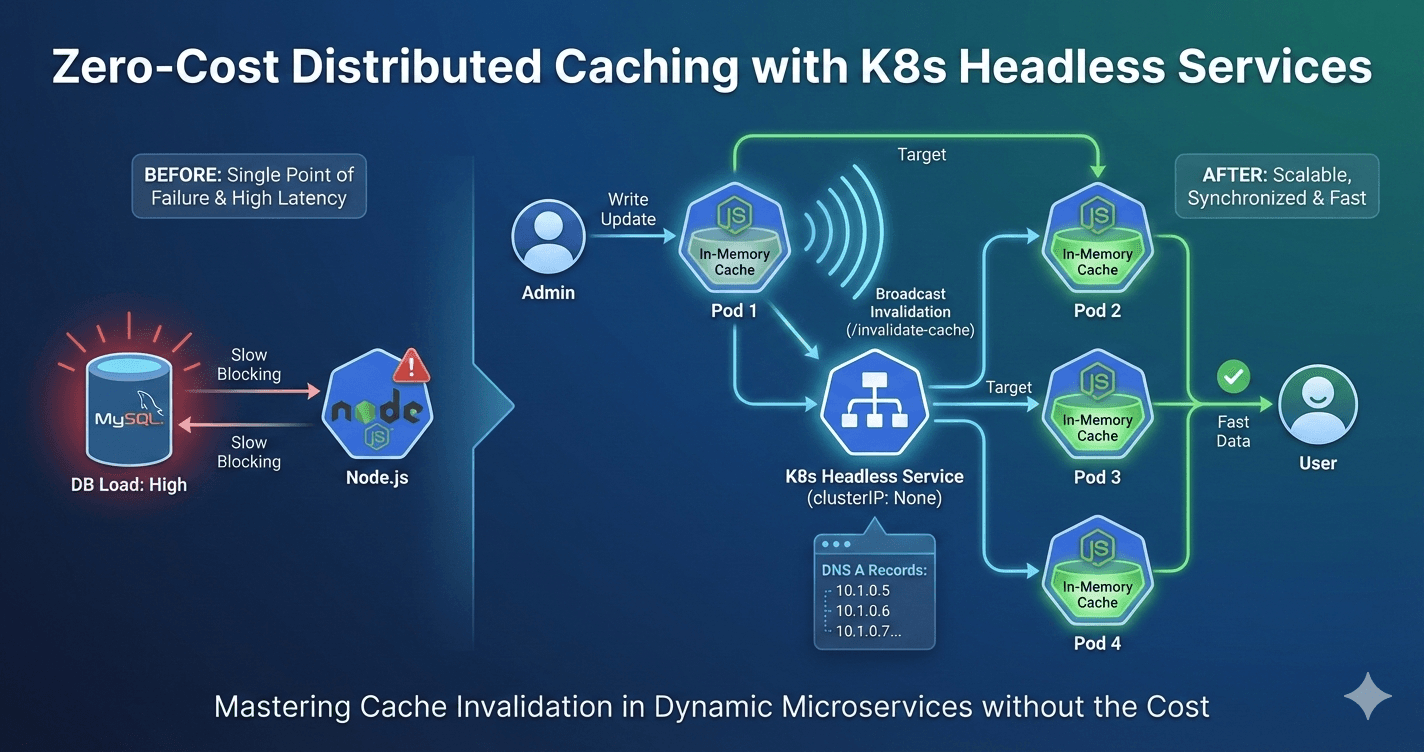
The $0 solution to a Distributed Cache Invalidation
Introduction At our current organization, earlier this year as we were looking at the errors at one of our signup API, we observed that nearly 5% of our requests were getting failed, all due to 400 BAD REQUEST errors, and the root cause was traced ba...

In every software system, we need unique Ids to distinguish between several objects from one another.
Recently, I wrote about the unique Id generation for a large scale distributed environment. In that article, we touched a little on UUIDs.
In this blog post, I will share an alternative to UUIDs that can help you fit the requirements that UUIDs fulfills and overcomes some of their shortcomings as well.
It is a tiny, secure, URL-friendly, unique string ID generator.
Nano ID has smaller size as compared to UUID. This size reduction impacts a lot. Making use of NanoID is easier for transferring information and storage space. In a large-scale system, these numbers can make a lot of difference.
NanoID uses a cryptographically strong API which is a lot safer compared to Math.Random() which are insecure. These API modules use unpredictable hardware generated random identifiers.
NanoID utilizes its very own "uniform formula" throughout the application of the ID generator instead of making use of an arbitrary % alphabet which is a popular mistake to make when coding an ID generator (The spread will not be even in some cases).
NanoID uses a larger alphabet resulting in short but unique identifiers.
NanoID permits designers to utilize personalized alphabets. This is another additional function of Nano ID. You can alter the literals or the dimension of the id as shown below (Specifying personalized letter as '1234567890ABCDEF' & dimension of the Id as 10):
import { alphabet } from 'nanoid';
const nanoid = alphabet ('1234567890ABCDEF', 10);
model.id = nanoid();
NanoID doesn’t much rely on any kind of third-party dependencies, which means, it ends up being a lot more steady which is helpful to maximize the package scope over time as well as make it much less vulnerable to the issues that come along with dependencies.
NanoID is available in various programs languages, which include - C#, C++, Dart & Flutter, Go, Java, PHP, Python, Ruby, Rust, Swift, etc.
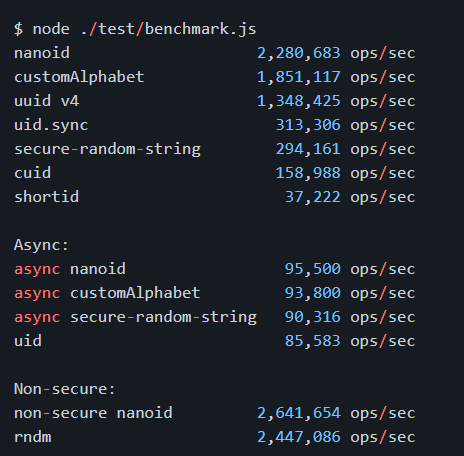
Generating both NanoID or UUID is pretty straightforward. In JavaScript, you have NPM packages that will help you to generate them. You can get NanoId from here => https://github.com/ai/nanoid
import { nanoid } from "nanoid";
model.id = nanoid() // X2JaSYP7_Q2leGI9b-MyA
nanoid(9); // "wMeKBp6th"
const alphabet = '0123456789ABCDEF';
generate(alphabet, 9); // F65BF3050
Even though it can generate over 2.2 million unique IDs per second with its default alphabet, there is still a chance of generating the same multiple Ids.
But what are the odds of that happening?
You can calculate that based on the given parameters easily here and here.
You'll notice that this probability comes out to be extremely small.
Imagine that a customer calls and is asked to provide the identifier, having to spell a complete NanoID is not a pleasant experience. When compared to UUID, NanoID is way shorter and readable but still cannot be used in such cases where the end customer needs to use it.
If you use NanoID as a table’s primary key, there will be problems if you use the same column as a clustered index. This is because NanoIDs are not sequential.
This is because the nature of NanoID(or even UUID) is that it's random and a clustered index physically orders the records by the key, so for every insert if there are indexes on the table, the database must make sure the new entry is also found via these indexes and to keep the index order and tree balance.
For this SQL has to reorder the records on disk and therefore remove clustering from this index. But when you have something sequential like time - clustering is almost free and easy to do after inserting a new record.
Any approach in a Software World is always going to be subjective. It’s up to your requirements to weigh in the tradeoffs and choose the approach that works for you. No design is concrete enough to continue forever, so given the constraints, we have chosen a certain design, and depending on how it works for us we might evolve it further as well.
👋 Thanks for reading and Happy learning…