Going Vernacular: Engineering Our Way to Process Multilingual Names

Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Introduction
At our current organization, earlier this year as we were looking at the errors at one of our signup API, we observed that nearly 5% of our requests were getting failed, all due to 400 BAD REQUEST errors, and the root cause was traced back to a regex check.
This regex was a constraint that our system allows only English characters for users to input their first and last names, yet many individuals opted to enter their names in their native languages. Particularly, these customers were the people who were interested in purchasing health policies from our platform hence making them a crucial segment of our user base.
In response to this, we decided to address the 5% case by enabling users to enter their names in any language they preferred. However, this brings up a lot of challenges that we need to solve.
Challenges
1. Data Storage Strategy
We rely on MongoDB for storage and retrieval of user names. While MongoDB allows storage for all UTF-8 compatible characters, the problem comes when dealing with search. For English names, our search operations utilize the simple collation method. The corresponding fields are appropriately indexed to optimize query performance.
While the option to implement a collation index for other languages also exists in MongoDB, this approach necessitates informing DB about the specific language for which we intend to search. The challenge here is that our user base spans many languages, with India alone having more than 20 diverse languages.
Since our objective was to extend support to at least all Indian languages, implementing collation indexes for every supported language would lead to an increased number of indexes and hence an increase in index size over time as well.
Additionally, this approach would place the responsibility on developers to remember to add an index for each new language as our language support expands, which is far from an efficient solution.
2. API Gateway Constraint
All our APIs are exposed behind an API gateway and just before the gateway forwards a request to the respective API service, an inbound policy verifies the user's authentication status. Once the user is authenticated, it retrieves basic user details such as name, mobile number, and other metadata, and appends it to a request header of that API.
A multitude of APIs rely on this user-specific data in headers for their further processing.
However, there's a restriction imposed by the gateway – it allows only ASCII characters for processing and inclusion in the headers. So we had to make sure even though the name is in any other language, the response we share must be exclusively in English.
Also, this process must remain fast, as any delay in authentication could lead to sluggish API performance.
3. External Partners' Challenge with Vernacular Names
Even if we started to accept names in multiple languages, there were our partners who had to accept those names from us. If they don't support multilingual names, the user journey breaks. One such was our payment partner. We had to make sure our payments team always received the English name even when users provided names in other languages.
Also, we wanted to avoid those annoying pop-ups prompting users to enter their names in English whenever we needed to. So keeping these problems in mind we had to build a viable solution.
Solutioning
While utilizing a third-party transliteration service might have been the easiest route, we opted to develop an in-house solution to control costs and maintain full control.
Considering the API gateway and the requirements of payment partners, it became clear that we needed to transform non-English names into English equivalents. However, presenting this English name to the user was counterintuitive – for example entering a name in Hindi, only to see it transformed into English upon logging in seemed contradictory.
Therefore, we developed a dual-naming strategy. The original fields, "firstName" and "lastName" would retain the user-entered names in their entered language, while we introduced two additional fields, "englishFirstName" and "englishLastName" dedicated to storing the English counterparts of these names. These English names could then be shared with the API gateway and our payment partners.
Coming back to the challenge of storing these names efficiently, we anticipated that managing collation indexes as the number of supported languages grew would become unmanageable. Additionally, searching would require specifying the collation for each query, creating an added layer of complexity. Hence, we decided to pivot away from this approach.
Our second approach involved using Unicode. As we aimed to support multiple languages without constraint, we recognized that Unicode could effectively represent characters in nearly every language. Consequently, we decided to store Unicode representations for first and last names in their respective MongoDB fields.
We just added another layer between our DB and the application that converts these Unicode strings to the original values in the local language while retrieving the names from DB and converting the local names to their respective English names for storing them in englishFirstName and englishLastName at the time of any insert or update.
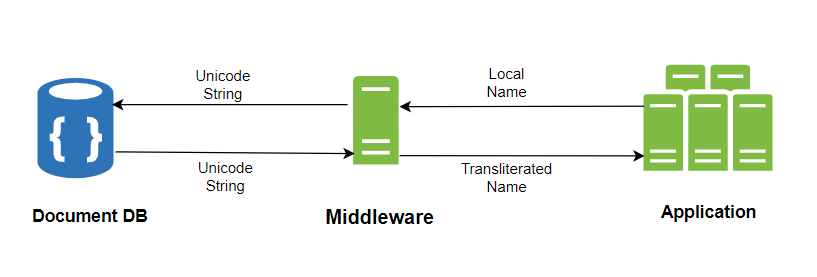
This strategy provided the flexibility we needed to manage multilingual names seamlessly.
Key Design Considerations
1. Unicode Optimization
Unicode representation typically comprises a 6 character string, with 'a' represented as 'U+0061' and 'P' as 'U+0050,' commonly commencing with 'U+00.' To conserve space in our database storage, we opted to omit the 'U+' prefix and leading zeros, optimizing our data storage.
2. Transliteration vs. Translation
Initially, our aim was transliteration, which requires converting names from one script to another while retaining their phonetic sound. For example, the Hindi word "प्रतीक्षा" should be transformed to "Partiksha" and not translated to its English equivalent i.e. "Wait". However, we recognized that Google Translate primarily focuses on translation, not transliteration. Again we didn't want to go directly for the paid Google transliterate service in our first iteration hence we developed our transliteration service using the free version of Google translate.
3. Contextual Enhancements
Another and the most crucial observation that we had was providing context to the Google Translate API that influenced its responses. To leverage this, we experimented with adding statement prefixes to non-English names to establish context. After a few hits and trials, we realized that for shorter names (less than 5 characters), a more extensive prefix statement didn't yield desirable results, and Google often returned the same Hindi word. For longer names, we employed lengthier statements, determining the optimal balance through trial and error.
Translating names normally led to their literal translation. For example "प्रतीक्षा" to "Wait" instead of "Pratiksha":
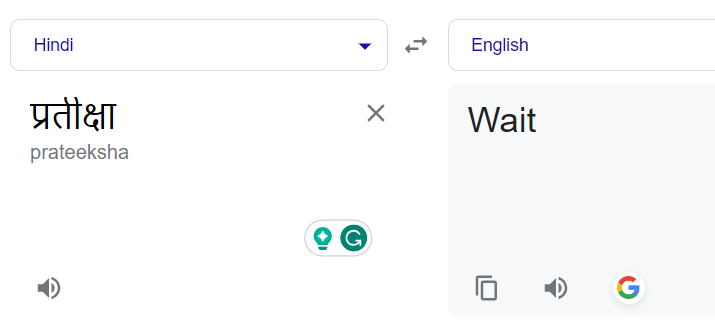
Adding a prefix statement corrected it:
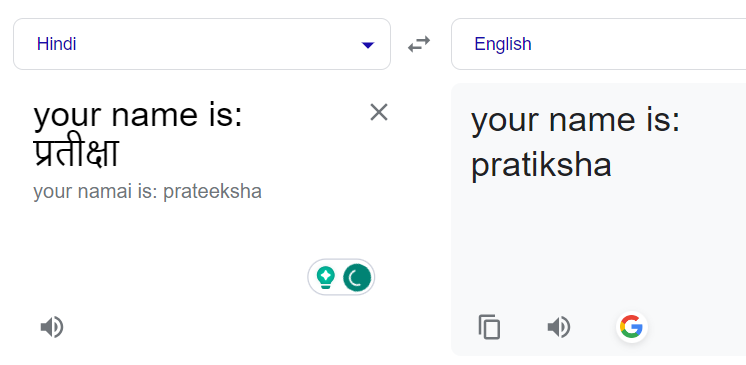
Initial Code
After our first iteration, we developed the below code for transliteration. Here we are using the @iamtraction/google-translate library which is a wrapper written over free Google translate API.
const translate = require('@iamtraction/google-translate');
function getGoogleTranslateText(localName) {
/*
Adding an English sentence before the name so that
it doesn't get translated to its literal meaning.
For eg परीक्षा to Exam instead of Pariksha.
*/
if (localName.length <= 5) {
return `name: ${localName}`;
}
return `your name is: ${localName}`;
}
async function translateNameToEnglish(localName) {
if (localName.match(/^[a-zA-Z ]+$/i)) {
// If the name is already in English just return
return localName;
}
try {
const res = await translate(getGoogleTranslateText(localName), {
to: 'en',
});
const translatedName = res.text.split(':')[1].trim();
return translatedName;
} catch (err) {}
// In case of error, Return the Unicode string
return localName;
}
Beta Release and Production Challenges
Once we built this, we released the feature in beta, and approximately 250 users signed up with non-English names within the first few days.
Upon simple eyeballing on translated texts, we found out that the process of converting the name from its local language to Unicode was working perfectly fine and users were able to view their names properly in the application in the language they preferred but we identified two issues as far as the process of transliteration to English was concerned:
Some names were incorrectly transliterated. This occurrence could be attributed to our dependence on Google Translate, a general translation service, rather than a specialized transliteration service.
Some names remained unaltered and were not transliterated. These names were returned in the same language as the original one. This meant adding context with prefix sentences before the translation was causing problems for specific names.
This prompted a further investigation that led us to another npm package called "unidecode," which converts Unicode to the original string. While initial tests with unidecode showed accuracy, they also revealed minor spelling discrepancies. In contrast, Google consistently delivered translations with correct spellings. We just needed to find a way of using the best of both worlds.
Hence, we incorporated unidecode into our algorithm as part of our solution.
Improved Solution
const translate = require('@iamtraction/google-translate');
const unidecode = require('unidecode');
const { isAlmostEqualStrings } = require('./levenshtein');
/**
*
* @param {String} localName
* @description Generates text for Google (shorter statement context for short names) based on localName length
* @returns {String} returns text to translate
*/
function getGoogleTranslateText(localName) {
/*
Adding an English sentence before name so that
it doesn't get translated to its literal meaning.
For eg परीक्षा to Exam instead of Pariksha.
*/
if (localName.length <= 5) {
return `name: ${localName}`;
}
return `your name is: ${localName}`;
}
/**
*
* @param {String} localName
* @description Give an ALMOST transliterated name
* @returns {String} returns a converted transliterated name from the local language
*/
function transliterate(localName, googleTranslatedName) {
const decodedName = unidecode(localName);
if (
decodedName &&
Array.from(decodedName)[0]?.toLowerCase() !==
Array.from(googleTranslatedName)[0]?.toLowerCase() &&
!isAlmostEqualStrings(decodedName, googleTranslatedName)
) {
return decodedName;
}
return googleTranslatedName;
}
/**
*
* @param {String} Input non English string
* @description translates non-english string to English
* @returns {String} returns translated string
*/
async function translateNameToEnglish(localName) {
if (!localName || localName.match(/^[a-zA-Z ]+$/i)) {
// If name is already in English just return
return localName;
}
try {
const res = await translate(getGoogleTranslateText(localName), {
to: 'en',
});
const translatedName = res.text.split(':')[1].trim();
return transliterate(localName, translatedName);
} catch (err) {}
// In case of error, Return original string
return localName;
}
After obtaining the translated name, we feed it into the recently introduced transliterate function. Inside this function, our initial step involves extracting the decoded string using the Unidecode library. However, the crux of the matter arises: How do we determine which result to prioritize, i.e., the decoded string or the translated string?
To tackle this, we implemented Levenshtein Distance, an algorithm that calculates the similarity between two strings.
Initially, we check if the first character of the decoded name matches the first character of the translated name. If it's not, then for sure the translated name was incorrect hence we return the decoded name, even though it might contain minor spelling discrepancies it's better to use that than the incorrect translation.
If it does match then we go for the Levenshtein Distance algorithm.
The Levenshtein distance is a number that tells you how similar two strings are. The higher the number, the more dissimilar the two strings are
In the implementation, we have a function isAlmostEqualStrings that generates a value from 0 to 1 and returns true if the value is above a certain threshold. In our case, we set the threshold to 0.8
If the Levenshtein distance indicates a match exceeding 80%, we return the translated name; otherwise, we return the decoded name. This approach ensures that we prioritize accuracy, offering a reliable result based on the established similarity threshold.
This updated algorithm substantially reduced the above mentioned issues. Even though it's not 100% accurate it solved our 5% cases very well.
Conclusion
The algorithm developed was entirely in-house and incurred no costs. While investing in a paid solution might have potentially offered better results, wise engineering decisions taken iteratively and a handful of clever hacks played a vital role in both reducing costs and efficiently resolving the specific problem we had.
The complete code for the above implementation along with the Levenshtein Distance algorithm can be found on GitHub (contributions/corrections are welcome).
With this, we come to the end of the article. My DMs are always open if you want to discuss further on any tech topic or if you've got any questions, suggestions, or feedback in general:
Happy learning!