Generating unique IDs in a Large scale Distributed environment
Learn how to create unique IDs for a distributed system at a large scale using the Twitter snowflake

Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Introduction
Recently at work, We were looking for a way to generate unique IDs across a distributed system that could also be used as the primary keys in the MySQL tables.
We knew in a single MySQL database we can simply use an auto-increment ID as the primary key, But this won’t work in a sharded MySQL database.
So I looked at various existing solutions for this and finally learned about Twitter Snowflake - a simple 64-bit unique ID generator.
Why don't you use UUID? 🤔
UUIDs are 128-bit hexadecimal numbers that are globally unique. The chances of the same UUID getting generated twice are negligible.
The problem with UUIDs is that they are very big in size and don’t index well. When your dataset increases, the index size increases as well and the query performance degrades.
Another problem with UUIDs is related to the user experience. Eventually, our users will be needed that unique identifiers. Imagine that a customer calls Customer Service and is asked to provide the identifier. Having to spell a complete UUID is not a pleasant experience.
Twitter snowflake ❄
Twitter snowflake is a dedicated service for generating 64-bit unique identifiers used in distributed computing for objects within Twitter such as Tweets, Direct Messages, Lists, etc.
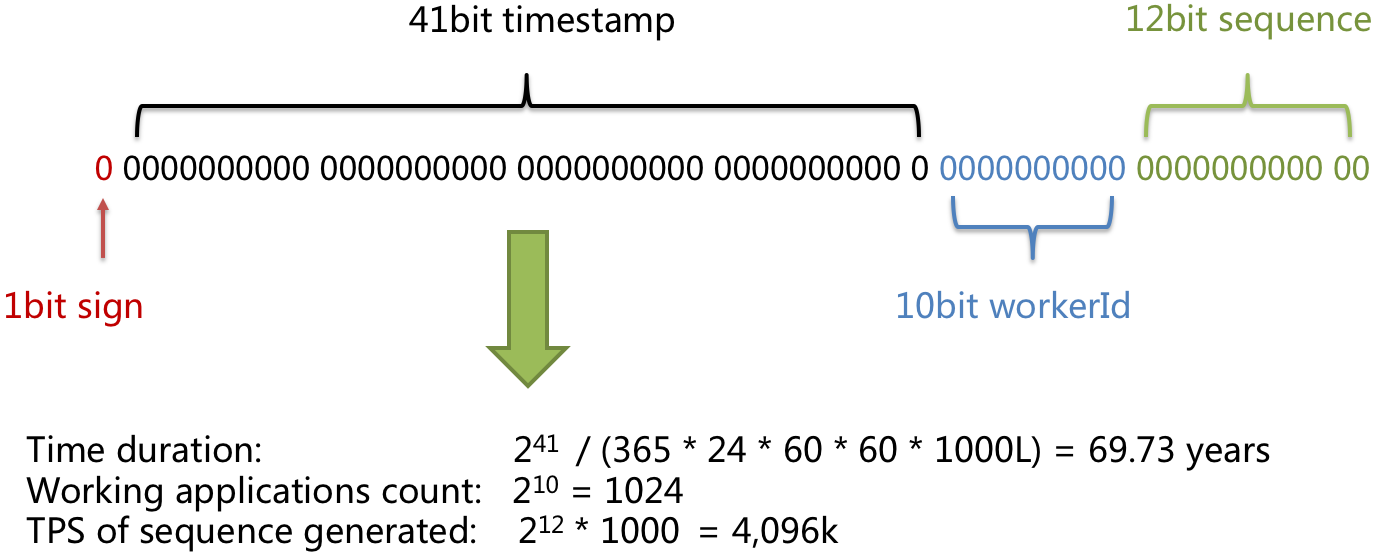
These IDs are unique 64-bit unsigned integers, which are based on time. The full IDs are made up of the following components:
Epoch timestamp in millisecond - 41 bits (gives us 69 years with respect to any custom epoch)
Configured machine/node/shard Id - 10 bits (gives us up to total of 210 i.e 1024 Ids)
Sequence number - 12 bits (A local counter per machine that sets to zero after every 4096 values)
The extra 1 reserved bit at the beginning which is set as 0 to make the overall number as positive.
Since these use the timestamp as the first component, therefore, they are time sortable as well. Another benefit is its High Availability.
By default, 64-bit unsigned integers (long) will generate an Id whose length is 19, but sometimes it may be too long, our use case needed an Id whose length should not be greater than 10.
This article will share a simplified version of the unique ID generator that will work for any use-case of generating unique IDs in a distributed environment based on the concepts outlined in the Twitter snowflake service.
Coding time ⌚
In our case, the full ID will be composed of a 20-bit timestamp, 5-bit worker number, and 6-bit sequence number.
The remaining 1-bit is the signed bit and it is always set to 0 to make the final value positive.
Our microservices can use this Random number generator to generate IDs independently. This is efficient and fits in the size of a int (4 Bytes or 32 bits).
Here is the complete code in Java (Inspired by Twitter snowflake, code credits) -
Step 1 - We initialize the number of bits that each component will require :
public class Snowflake {
// Sign bit, Unused (always set to 0)
private static final int UNUSED_BITS = 1;
private static final int EPOCH_BITS = 20;
private static final int NODE_ID_BITS = 5;
private static final int SEQUENCE_BITS = 6;
private static final int maxNodeId = (int)(Math.pow(2, NODE_ID_BITS) - 1);
private static final int maxSequence = (int)(Math.pow(2, SEQUENCE_BITS) - 1);
// Custom Epoch (Fri, 21 May 2021 03:00:20 GMT)
private static final int DEFAULT_CUSTOM_EPOCH = 1621566020;
private volatile int lastTimestamp = -1;
private volatile int sequence = 0;
// Class Constructor
public Snowflake() {
this.nodeId = createNodeId();
this.customEpoch = DEFAULT_CUSTOM_EPOCH;
}
Here, we are taking custom epoch as of Fri, 21 May 2021 03:00:20 GMT.
EPOCH_BITS will be 20 bits and is filled with a current timestamp in seconds (You can also use millisecond if there is a possibility of multiple numbers of requests per second).
NODE_ID_BITS will be 5 bits and is filled using the Mac address.
SEQUENCE_BITS will be 6 bits and will act as a local counter which will start from 0, goes till 63, and then resets back to 0.
Step 2 - Creating a synchronized function to generate the IDs :
public synchronized int nextId() {
int currentTimestamp = (int) (Instant.now().getEpochSecond() - customEpoch);
if(currentTimestamp < lastTimestamp) {
throw new IllegalStateException("Invalid System Clock!");
}
lastTimestamp = currentTimestamp;
return currentTimestamp << (NODE_ID_BITS + SEQUENCE_BITS) | (nodeId << SEQUENCE_BITS) | sequence;
}
Wait, why are we doing these Left Shifts & Logical OR operations?
This is because Integer is represented by 32 bits and initially all are set to 0. To fill these bits we have to take each component separately, so first we took the epoch timestamp and shift it to 5 + 6 i.e 11 bits to left. Doing this has filled the first 21 bits with the first component (remember the first bit is always set to zero to make the overall number positive). The remaining 11 bits are still 0 and hence again we repeat the same thing with logical OR & the other two components as well thereby filling all the 32 bits and forming the complete number.
Step 3 - Utility function to generate the node id using the system’s MAC address:
private int createNodeId() {
int nodeId;
try {
StringBuilder sb = new StringBuilder();
Enumeration<NetworkInterface> networkInterfaces = NetworkInterface.getNetworkInterfaces();
while (networkInterfaces.hasMoreElements()) {
NetworkInterface networkInterface = networkInterfaces.nextElement();
byte[] mac = networkInterface.getHardwareAddress();
if (Objects.nonNull(mac))
for(byte macPort: mac)
sb.append(String.format("%02X", macPort));
}
nodeId = sb.toString().hashCode();
} catch (Exception ex) {
nodeId = (new SecureRandom().nextInt());
}
nodeId = nodeId & maxNodeId;
return nodeId;
}
}
How it works? 💡
Let’s now understand its working with an example -
Let’s say it’s Sun, 23 May 2021 00:00:00 GMT right now. The epoch timestamp for this particular time is 1621728000.
First of all, we adjust our timestamp with respect to the custom epoch-
currentTimestamp = 1621728000- 1621566020 = 161980(Adjust for custom epoch)
So to start our ID, the first 20 bits of the ID (after the signed bit) will be filled with the epoch timestamp. Let's this value with a left-shift :
id = currentTimestamp << (NODE_ID_BITS + SEQUENCE_BITS )
Next, we take the configured node ID/shard ID and fill the next 10 bits with that
id = id | nodeId << SEQUENCE_BITS
Finally, we take the next value of our auto-increment sequence and fill out the remaining 6 bits -
id = id | sequence // 6149376
That gives us our final ID 🎉
And that’s it! Primary keys that are unique across our application!
Summary 📊
This article showed you a simple solution of how to generate a snowflake id whose length is >=7 and <=10.
By the way, you can adjust the bit count of the 3 components to adapt to your work.
NOTE : We should keep the generator as a singleton, it means that we should only create the single instance of SequenceGenerator per node. If not, it may generate some duplicate Ids.
Not only did twitter used it, Discord also uses snowflakes, with their epoch set to the first second of the year 2015.
Instagram uses a modified version of the format, with 41 bits for a timestamp, 13 bits for a shard ID, and 10 bits for a sequence number.
I hope this will help you! Thanks for reading :))
Other Articles You Might Like 🙂
Useful Resources To Learn Web Development & To Create Your Website - Resources I found helpful in my web development journey.
Chrome extensions I use to enhance my GITHUB experience - Here are 7 extensions I use to improve my Github experience.
The Most Famous Coding Interview Question - Learn about what's the most asked coding interview question and how you can approach it in the best possible way.
Welcome to the world of "NFTs" - Learn about what are NFTs and Why are they suddenly becoming the next big thing.
What is Blockchain Technology? Learn by creating one - Want to know how blockchain works? Learn here by creating one.