

Hyperloglog: Cardinality Estimation

A
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Search for a command to run...
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
No comments yet. Be the first to comment.
Group of data structures that are extremely useful for big data and streaming applications.
A lot of time you will come across a problem in computer science when you want to find whether an element is present in a set of already existing elements. For example, if I want to know whether the word "cat" is present in our database which is say,...
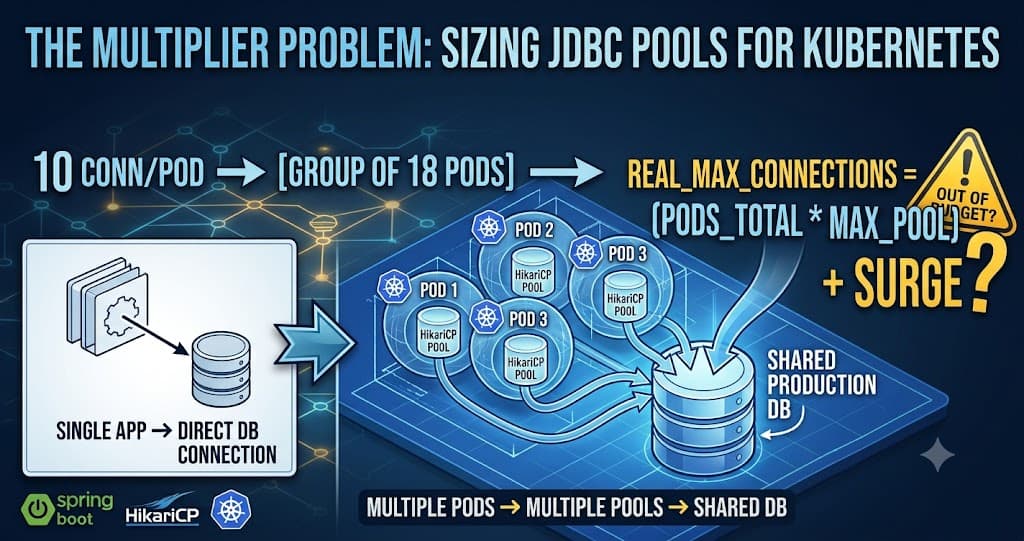
Stop guessing your maximum-pool-size. Learn how to calculate limits backwards from your database
Learn what Jib is, how it works, and when to use Jib vs Dockerfile. A guide with real-world scenarios

A prod debugging story you’ll probably relate to

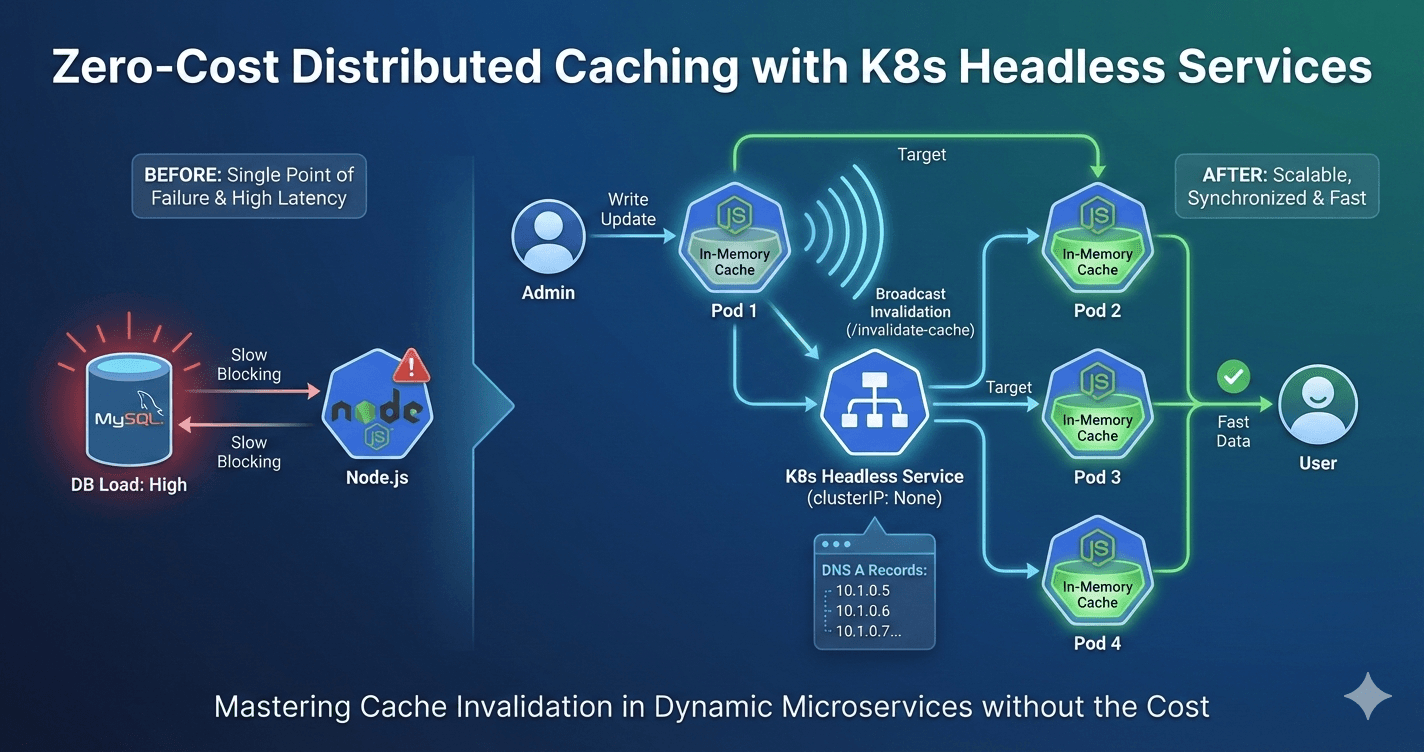
The $0 solution to a Distributed Cache Invalidation
Introduction At our current organization, earlier this year as we were looking at the errors at one of our signup API, we observed that nearly 5% of our requests were getting failed, all due to 400 BAD REQUEST errors, and the root cause was traced ba...

 Hyperloglog is another probabilistic data structure (just like bloom filter) that is used to find the cardinality of a multiset(can have multiple occurrences of the same element). It is being used in most of big data systems to compute the count of distinct elements.
Hyperloglog is another probabilistic data structure (just like bloom filter) that is used to find the cardinality of a multiset(can have multiple occurrences of the same element). It is being used in most of big data systems to compute the count of distinct elements.
The problem is simple - you are given a list of elements let's say "user_id" of customers that visit a particular website on a day, you have to find how many unique customers are there in a list.
The naive approach here would be to traverse the list and keep saving the user ids in a different set if we haven't seen it already; else just ignore it. Finally, the length of that new set that we created is the total number of unique customers or the cardinality of the original list we had.
So, what's the complexity of this approach? Because we have to traverse the whole list and one by one check if the element already exists with us or not, this process will have the time complexity of O(n) (n is the number of elements in a list) and the space complexity? - it turns out that in a worst-case scenario where every element in the initial list is already unique, it will give us the space complexity of O(n).
These space and time complexities are fine up to a limit but definitely not good for scale where there is large traffic and every day millions or billions of customer visits the website.
This is where hyperloglog comes in and solves the problem of space at the cost of some error rates in the final answer of getting cardinality but we are OK with it as long as error rates are low and also at a large scale we rarely want to know the exact traffic we are getting, most of the times we are fine to have an approximation of the cardinality, hence an estimation can serve our purpose.
HyperLogLog computes the approximation with very little memory and time. It is able to estimate cardinalities of large systems with a typical error of 1%, using 1.5 kB of memory.This is achieved by using a hash function which is applied to every element that is to be counted in such a way that it evenly randomizes the bits.
Continuing with the example where we have to find the unique number of customers visiting a website on a particular day let us suppose after hashing the user ids we got a 64-bit number.
Now in a 64-bit random number, the probability that we will get a '0' at the end is about half a number of times(because it can either be 1 or 0). And similarly, the probability of getting the last two bits of that number to '0' is 1/4. So, to generalize this if we want the last 'x' digits of a binary number to be '0' we have to actually go through 2^x numbers to get to that.
For applying it practically, we will look at each server that holds the user id of a customer, hash it, find the maximum number of trailing zeros(it can either be leading or trailing zeros), let's say we got 'n' number of maximum trailing zeros than the total number of unique users according to our assumption will be approximately 2^n.
But there is one catch, we might have to deal with a really big variance with this approach. Let me depict this with an example: Suppose we have three requests and the last 5 digits are 11000,00011,11100 now we have 3 as maximum zeros at the end so according to what we just discussed we will get the total unique user as 2^3 which is 8 but actually, we had only 3 requests.
In order to overcome this variance issue what we can do is to use buckets to put these requests in.
For this we can use the leading 'x' bits of the same hashed number of which we were initially using the trailing zeros (we also can hash this number again with n hash functions but sometimes it's better to save the extra computational power as hashing is expensive) let us suppose we take first two digits of the binary number as our bucket number which means we can have a bucket of size 4 (00,01,10,11) and we have the following four requests with us:
10000,01000,01011,00110 - we are taking 'x' as 2(leading digits for determining bucket number of a particular request) which means the first request will go to bucket-2(01), request number two and three will go to bucket-1(01) and the final request will go to bucket-0(00).
This time we will take the maximum trailing zeros from each bucket and find their mean i.e in bucket-0 we have '1' trailing zeros, in bucket-1 we have 2 requests and the maximum trailing zeros out of those two are '3' and for bucket-2 we again have '3' zeros and finally, for bucket-3 we have no requests so maximum trailing zeros we got from bucket-3 is 0.
So the mean will be (1+3+3+0)/4 which is equal to around 1.8 and 2 raised to the power 1.8 is approximately 4, hence our estimation is correct.
For further improving accuracy there is a formula - which is to multiply your answer you got above with the number of buckets you used and 0.79402. This special number 0.79402 is actually derived in this paper by Flajolet. Statistical analysis shows that our method of finding cardinality is biased towards larger estimates, so to improve accuracy we have to use :
2^{mean} * number_of_buckets * 0.79402
The error rates of the hyperlolog estimation algorithm are really low which is 1.3/root(m) where m is the bucket size.
Again in our case, since the bucket size was 4, the error percent is (1.3/2) ~ 65%
As the requests increase so will the bucket size and with these formulae, our error rate will drop drastically and also compared to our naive approach the space requirement is very very less in case we process billions of requests, which is O(log(log(n)) since we only have to store the number of zeroes that we've come across in the end i.e atmost 64 zeroes in our case after going through 2^{64} numbers and these 64 zeroes can be represented by using only 7 bits (from 0 to 128) So the log(log(2^64)).
Hyperloglog also reduces the time complexity to O(1) this is because in a distributed system you now only have to merge the buckets from each server which is not a heavy task.
Here's the link to the full code.
I have taken python's hashlib library's SHA-256 algorithm for hashing and then converted the hexadecimal value to binary 256-bit integers which are obviously will not act as a good hash function but will serve our purpose of demonstrating how the algorithm works.