

Finding a Needle in Haystack: Fixing Mysterious Bad Gateway

A
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Search for a command to run...
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
No comments yet. Be the first to comment.
Bits and Pieces I learned on how to build and scale a distributed system. All the posts in the series belong to the real problems I faced during my 9-5 and the solutions we went through with.
Introduction Any application that communicates with other resources over a network has to be resilient to transient failures. These failures are sometimes self-correcting. For example, a service that is processing thousands of concurrent requests can...
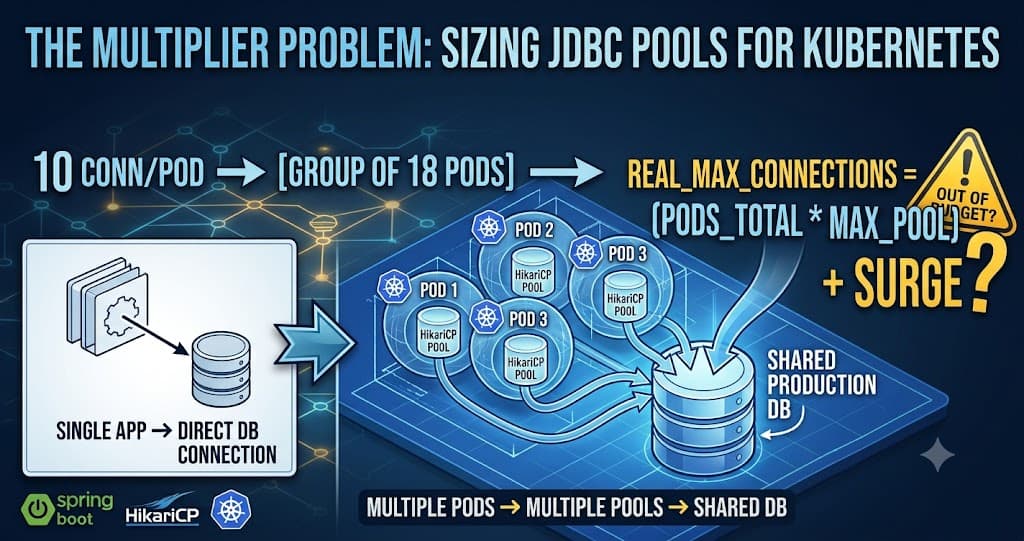
Stop guessing your maximum-pool-size. Learn how to calculate limits backwards from your database
Learn what Jib is, how it works, and when to use Jib vs Dockerfile. A guide with real-world scenarios

A prod debugging story you’ll probably relate to

The $0 solution to a Distributed Cache Invalidation
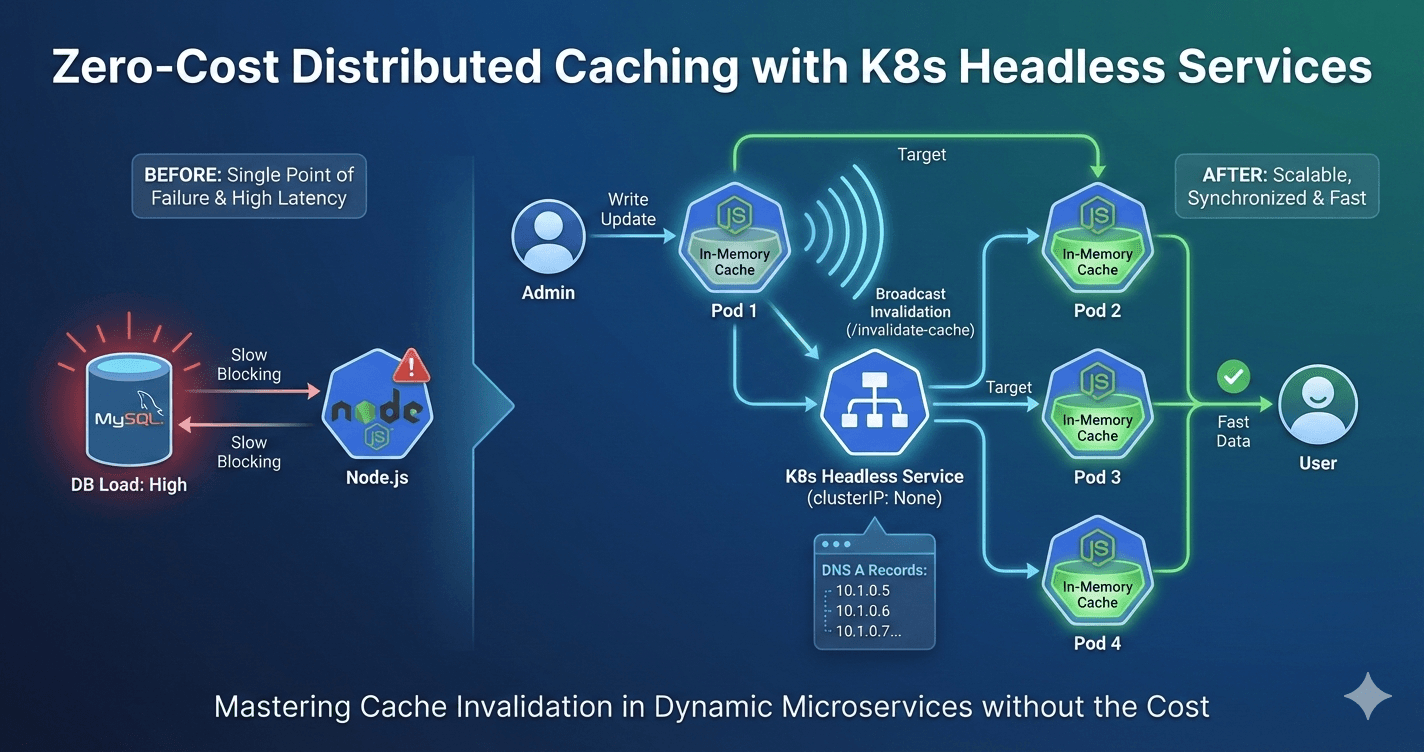
Introduction At our current organization, earlier this year as we were looking at the errors at one of our signup API, we observed that nearly 5% of our requests were getting failed, all due to 400 BAD REQUEST errors, and the root cause was traced ba...

At my current org, we have many applications running behind the API gateway that interacts with the outside world using REST APIs. To track server-side failures we built an alert system that nudges every time we get any 5XX error.
As soon as we made the alert system live, we started noticing a few HTTP 502 “Bad Gateway” errors occurring every day but intermittently.
As per RFC7231, the 502 (Bad Gateway) status code indicates that the server while acting as a gateway or proxy, received an invalid response from an inbound server it accessed while attempting to fulfill the request.
With very little known information, I began chasing down the RCA for these failures.

As I started debugging the issue I wanted first to check what was going on in the application at the time when the particular request arrived. However, I discovered that this failed request never reached the server-side application.
We also have a proxy server sitting in between our API gateway and the application so I checked the logs of that as well and fortunately, I was able to track the request there.
I observed the request despite coming from the API gateway, the response sent was 502, without even communicating with my application.
Next, I checked the throughput when such a response was sent as I thought maybe there was a limitation in the number of concurrent requests our application can handle. But the result was again surprising because even when the throughput was < 1000 TPM (Transactions Per Minute), the 502 error persisted and we had already observed our applications working well even at a TPM of well over 5000.
Based on these findings, I realized that issue is not with our application code but with how our proxy server interacts with my application. So I started diving deep into how HTTP connections are made during the request-response cycle.
In the realm of web communication, HTTP (Hypertext Transfer Protocol) initiates a unique TCP (Transmission Control Protocol) connection for every request. Setting up a TCP connection requires a three-step handshake process with the server before transmitting data. Once the data transmission is finished, a four-step process is implemented to terminate the same connection.
In some scenarios where limited data is transmitted, the three and four-step processes involved in establishing and terminating TCP connections can add a significant overhead. To address this issue, rather than opening and closing a socket for each HTTP request, it is possible to keep a socket open for a more extended period and leverage it for multiple HTTP requests.
This mechanism is known as HTTP keep-alive, which permits clients to reuse existing connections for several requests. The decision of when to terminate these open TCP sockets is managed by timeout configurations on either the client or target server or both. This approach improves the efficiency of web communication and reduces latency.
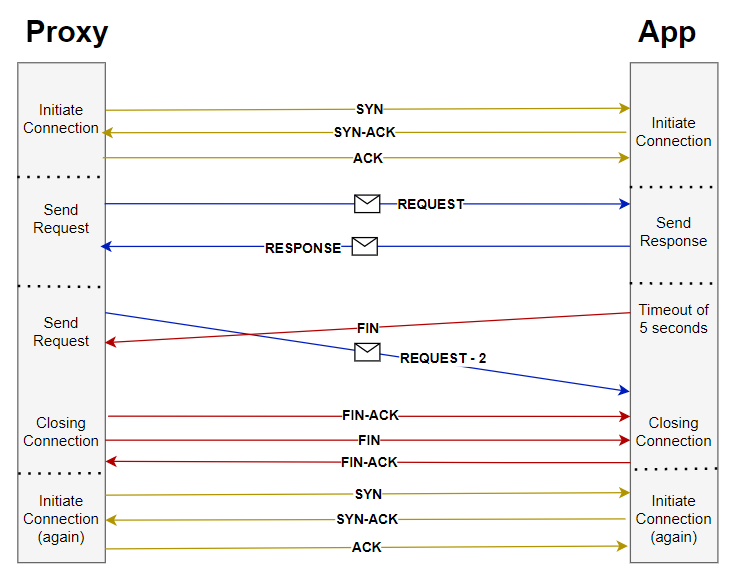
An important point here to notice is that for a short amount of time, there is a possibility that a connection can be “half-open”, in which one side has terminated the connection but the other has not. The side that has terminated can no longer send any data into the connection, but the other side still can. The terminating side continues reading the data until the other side terminates as well.
Now coming back to our story, the proxy server acts as a messenger passing requests and responses back and forth. If the service returns an invalid or malformed response, rather than transmitting that meaningless information to the client, the proxy server sends a 502 error message.
This suggests that our application might have attempted to terminate the TCP connection, but the proxy server was unaware of this and continued to send the request to the same socket. This provided us with a critical hint in our investigation.
The 502 Bad Gateway error could occur when the proxy server sends a request to the application, and simultaneously, the service terminates the connection by sending the FIN segment to the same socket. The proxy socket acknowledges the FIN and starts a new handshake process.
Meanwhile, the socket on the server side has just received a data request referring to the previous (now closed) connection. As it is unable of handling it, it sends a RST segment back to the proxy server. The proxy server then returns a 502 error to the user.
Based on this hypothesis, we found the default HTTP keep-alive time. While the proxy server's keep-alive time was set at 75 seconds, our application had a keep-alive of only 5 seconds. This suggests that after 5 seconds, our application could close the connection, and while this process is ongoing, the proxy server could receive a request. As it has not yet received the FIN, it sends the request down the dead connection, receives nothing in response, and therefore throws a 502 error.
To verify this hypothesis, I modified the HTTP keep-alive timeout of our application to 1 ms in our development environment. We then conducted load testing on our APIs and found a significant number of API failures due to the same 502 error. This confirmed our initial hypothesis.
A possible solution is to ensure that the upstream (application) idle connection timeout is longer than the downstream (proxy) connection timeout.
In practice, this can be achieved by increasing the keep-alive time of the application server to a value greater than the proxy's connection timeout. For example, in our setup, I have increased the server's keep-alive time from 5 seconds to 76 seconds, which is 1 second longer than the proxy server's connection timeout.
By doing so, the downstream (proxy) server becomes the one to close the connections instead of the upstream server. This ensures that there is no race condition between the two servers and eliminates the possibility of a 502 error caused by a closed connection. Therefore, setting appropriate upstream and downstream timeouts is crucial for the smooth functioning of web applications.
const express = require('express');
const app = express();
const server = app.listen(3000);
server.keepAliveTimeout = 76 * 1000 // Time in ms
Theoretically, this race condition can occur anytime when the connections are reused & if the upstream service drops connections before the downstream.
In my case, it was the proxy server that pre-connects to all the backend servers, and the TCP connection persists for reusing for further HTTP requests. The Keep-Alive time of this connection was 75 seconds from the proxy and 5 seconds from the app server.
This was causing a condition where the proxy thinks a connection is open, but the backend closes it. And when it sends the request down the same connection, instead of getting the TCP ACK for the sent request, the proxy gets TCP FIN (and eventually RST) from the upstream.
The proxy server then just gives up on such requests and responds immediately with HTTP 502 error to the client. And this is completely invisible on the application side! That's why no application logs were visible to us.
To mitigate this you can either make sure the upstream (application) idle connection timeout is longer than the downstream (proxy) connection timeout OR implement retries on HTTP 5xx errors from the API gateway.
I hope you found it helpful. Comments or corrections are always welcome.