

Building Resilient Systems: Retry Pattern in Microservices

A
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
Search for a command to run...
Senior Software Engineer. I write about practical tips and epic stories about my experiences in the field of computer science and engineering!
No comments yet. Be the first to comment.
Bits and Pieces I learned on how to build and scale a distributed system. All the posts in the series belong to the real problems I faced during my 9-5 and the solutions we went through with.
Important points to consider, Relational vs Non-relational Database, CAP theorem, and more!
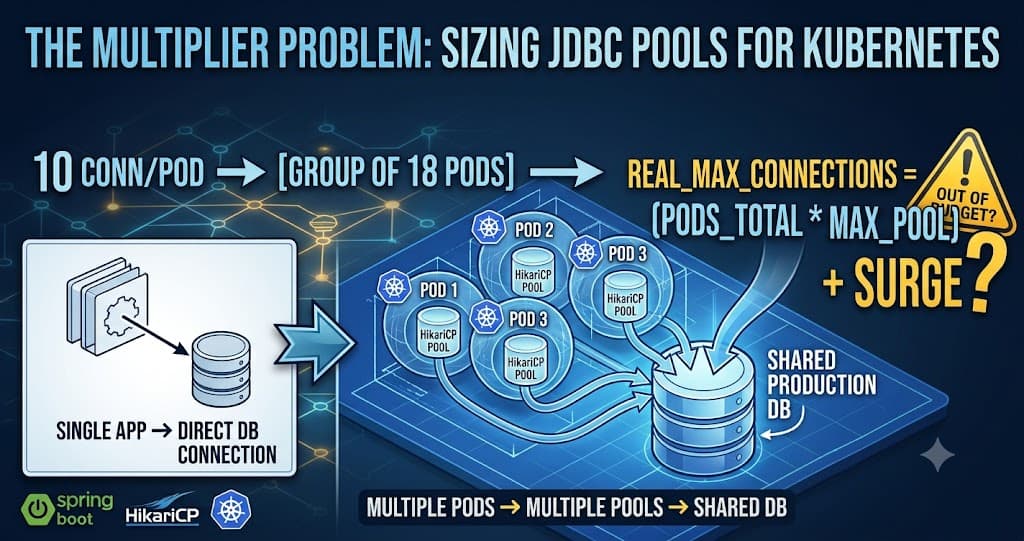
Stop guessing your maximum-pool-size. Learn how to calculate limits backwards from your database
Learn what Jib is, how it works, and when to use Jib vs Dockerfile. A guide with real-world scenarios

A prod debugging story you’ll probably relate to

The $0 solution to a Distributed Cache Invalidation
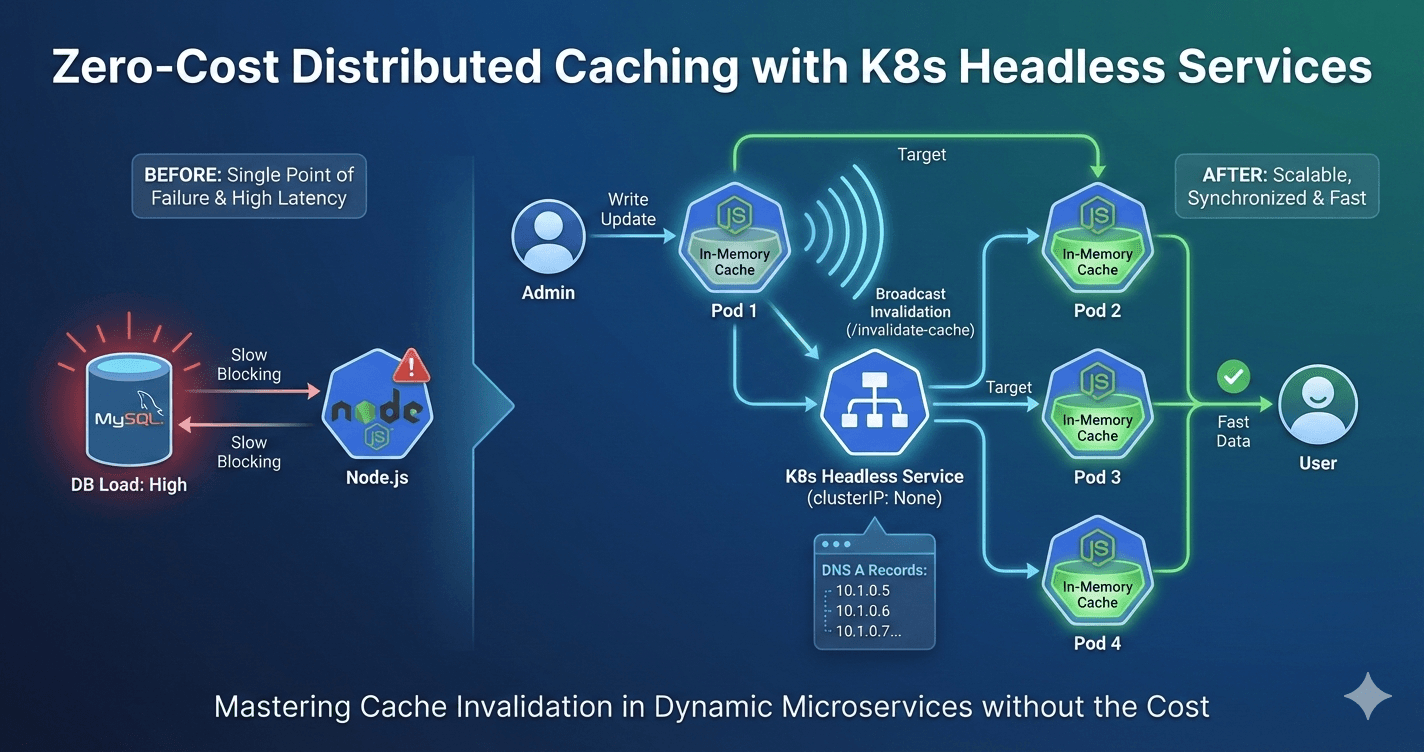
Introduction At our current organization, earlier this year as we were looking at the errors at one of our signup API, we observed that nearly 5% of our requests were getting failed, all due to 400 BAD REQUEST errors, and the root cause was traced ba...

Any application that communicates with other resources over a network has to be resilient to transient failures.
These failures are sometimes self-correcting. For example, a service that is processing thousands of concurrent requests can implement an algorithm to temporarily reject any further requests until its load gets reduced. An application that is trying to access this service may initially fail to connect, but if it tries again it might succeed.
While designing any system it is essential to make it resilient against such failures. In this article, we will look at one of the many ways of achieving it using Retries.
At our current organization, we use this mechanism throughout our microservices to make sure that we handle failures and at the same time, provide the best of our services to our customers.
Let’s start by first defining what we mean by failures.
Failures can be caused by numerous reasons while our services communicate with each other over a network. Some examples of types of failures are:
A slow response / No response at all
A response in the incorrect format
A response containing incorrect data
In planning for failures, we should seek to handle each of these errors.
Retry is a process of automatically repeating a request in case any failure is detected. This helps return fewer errors to the users, improving the consumer experience on our application.
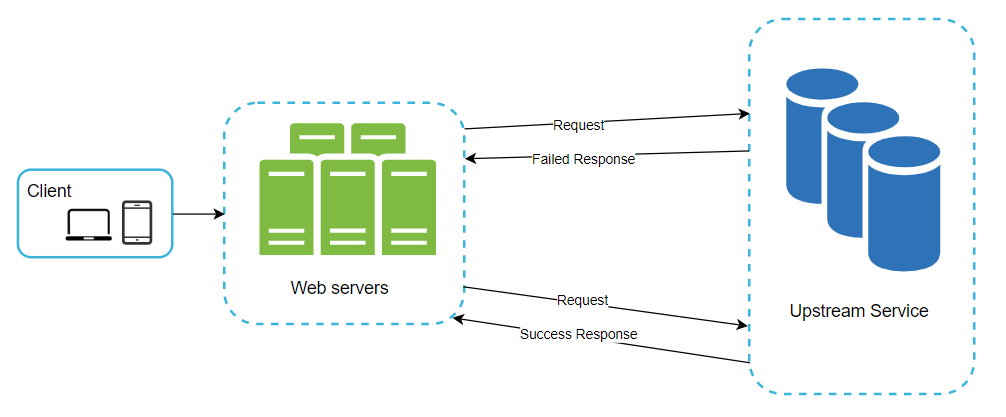
The only caveat when it comes to retrying is that multiple requests to the same resource should have the same effect as making a single request i.e the resource should be idempotent.
In REST APIs,
GET,HEADandOPTIONSmethods generally do not change the resource state on the server and hence are mostly retryable.
Ideally, we should only retry a failed request when we know it has any possibility of succeeding the next time otherwise it will just be a waste of resources (CPU, Memory, and Time).
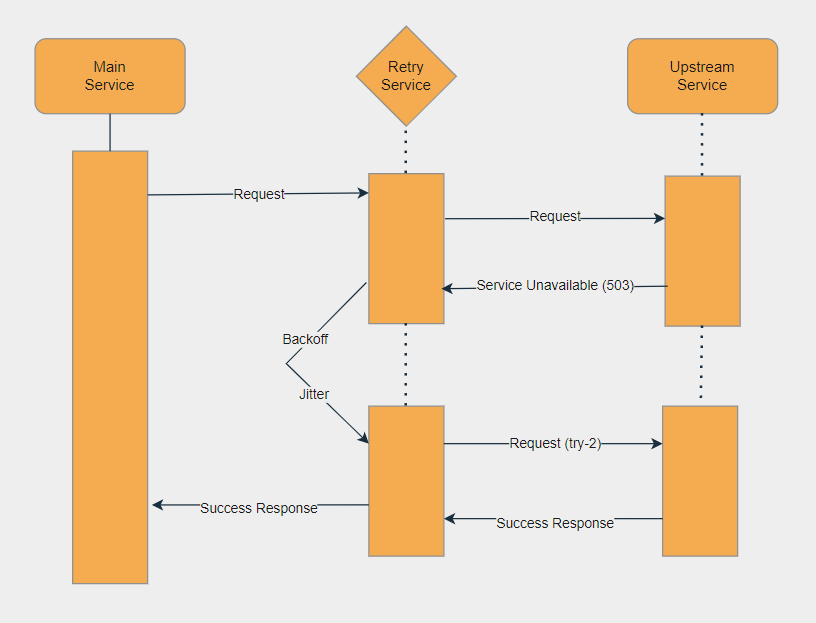
For example, you might get an error with status code 503 (Service unavailable) when the server had an unexpected hiccup while connecting to a DB host. A retry may work here if the second call to the upstream service gets a DB instance that is available.
On the other hand, retrying for errors with status code 401(Unauthorised) or 403 (Forbidden) may never work because they require changing the request itself.
The general idea is that if an upstream request fails, we immediately try again, and probably the second request will succeed. However, this will not always benefit us. The actual implementation should include a delay between the subsequent requests. We will discuss that in the next sections.
Consider what happens when we get 100,000 concurrent requests & all hosts of the upstream service are down at that instance. If we were to retry immediately, these 100,000 failed requests would retry immediately on a static interval. They would also be combined with new requests from the increasing traffic and could make the service down again.
This creates a cycle that keeps repeating until all the retries are exhausted and will also eventually makes the upstream service overwhelm, and might further degrade the service that is already under distress. This is a common computer science problem also known as the Thundering Herd problem.
To tackle this, we can introduce some delay in retrying a failed request.
The wait time between a request and its subsequent retry is called the backoff.
With backoff, the amount of time between requests increases exponentially as the number of retry requests increases.
The scenario we just discussed above is where having a backoff helps, it changes the wait time between attempts based on the number of previous failures.
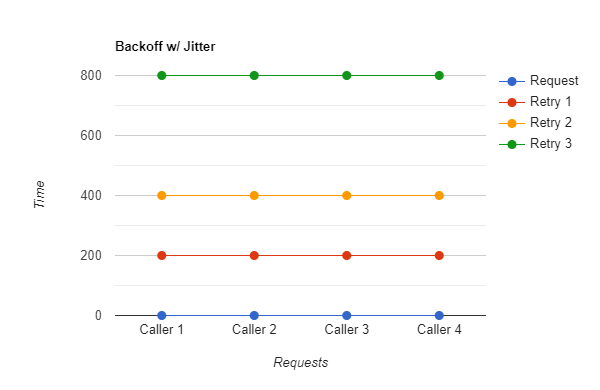
From the above figure, let's say the initial request goes at the 0th millisecond and fails with a retryable status code. Assuming that we have set up the backoff time of 200ms and neglecting the request-response time, the first retry attempt happens at 200th milliseconds (1*200ms). If this fails again, the second retry then happens at 400ms (2*200). Similarly, the subsequent retry happens at 800ms till we exhaust all the retries.
If any of the request failures are caused by the upstream service being overloaded, this mechanism of spreading out our requests and retries gives us a better chance of getting a successful response.
The Backoff strategy allows us to distribute the load sent to the upstream services. Yet, turns out it isn't always the wisest decision because all the retries are still going to be in sync which can lead to a spike on the service.
Jitter is the process of breaking this synchronization by increasing or decreasing the backoff delay to further spread out the load.
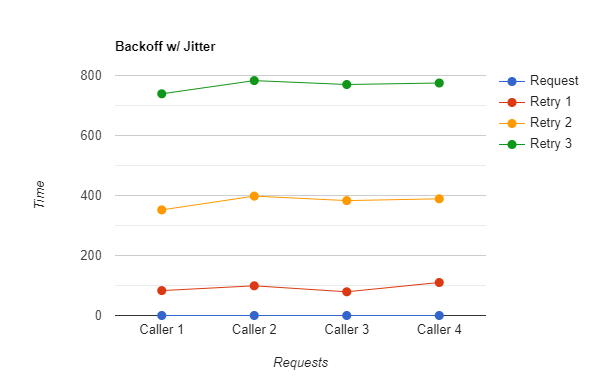
Coming back to our previous example, let’s say our upstream service is serving the maximum load that it can handle and four new clients send their requests which fail because the server could not handle that amount of concurrent requests. With only backoff implementation, let's say after 200 milliseconds we retry all 4 failed requests. Now, these retry requests would also fail again for the same reason. To avoid this, the retry implementation needs to have randomness.
Going through this AWS documentation that goes deep into the exponential backoff algorithm, we have implemented our retry mechanism using Axios interceptor
The example is written inside of a Nodejs application, but the process will be similar regardless of which JavaScript framework you’re using.
In this, we expect the following settings:
Total Retries The number of maximum retries you want before returning a failed response to the client.
Retry Status Codes The HTTP status codes that you want to retry for. By default, we have kept it on for all status codes >=500.
Backoff This is the minimum time we have to wait while sending any subsequent retry request.
axios.interceptors.response.use(
async (error) => {
const statusCode = error.response.status
const currentRetryCount = error.response.config.currentRetryCount ?? 0
const totalRetry = error.response.config.retryCount ?? 0
const retryStatusCodes = error.response.config.retryStatusCodes ?? []
const backoff = error.response.config.backoff ?? 100
if(isRetryRequired({
statusCode,
retryStatusCodes,
currentRetryCount,
totalRetry})
){
error.config.currentRetryCount =
currentRetryCount === 0 ? 1 : currentRetryCount + 1;
// Create a new promise with exponential backoff
const backOffWithJitterTime = getTimeout(currentRetryCount,backoff);
const backoff = new Promise(function(resolve) {
setTimeout(function() {
resolve();
}, backOffWithJitterTime);
});
// Return the promise in which recalls Axios to retry the request
await backoff;
return axios(error.config);
}
}
);
function isRetryRequired({
statusCode,
retryStatusCodes,
currentRetryCount,
totalRetry}
){
return (statusCode >= 500 || retryStatusCodes.includes(statusCode))
&& currentRetryCount < totalRetry;
}
function getTimeout(numRetries, backoff) {
const waitTime = Math.min(backoff * (2 ** numRetries));
// Multiply waitTime by a random number between 0 and 1.
return Math.random() * waitTime;
}
While making an Axios request you have to make sure to add the variables in the request configurations:
const axios= require('axios');
const sendRequest= async () => {
const requestConfig = {
method: 'post',
url: 'api.example.com',
headers: {
'authorization': 'xxx',
},
data: payload,
retryCount : 3,
retryStatusCodes: ['408', '429'],
backoff: 200,
timeout: 5000
};
const response = await axios(requestConfig);
return response.data;
}
When configuring the retry mechanism, it is important to tune the total retries, and maximum delay together. The goal is to tailor these values keeping in mind the worst-case response time to our consumers.
Pictorially this is how it will work:
For Java based applications, the same can be done using resilience4j
In this post, we looked at one of the many service reliability mechanisms: Retries. We saw how it works, how to configure it and tackle some of the common problems with retries using backoff and jitter.
I hope you found it helpful. Comments or corrections are always welcome.
GitHub Link for the above source code can be found here